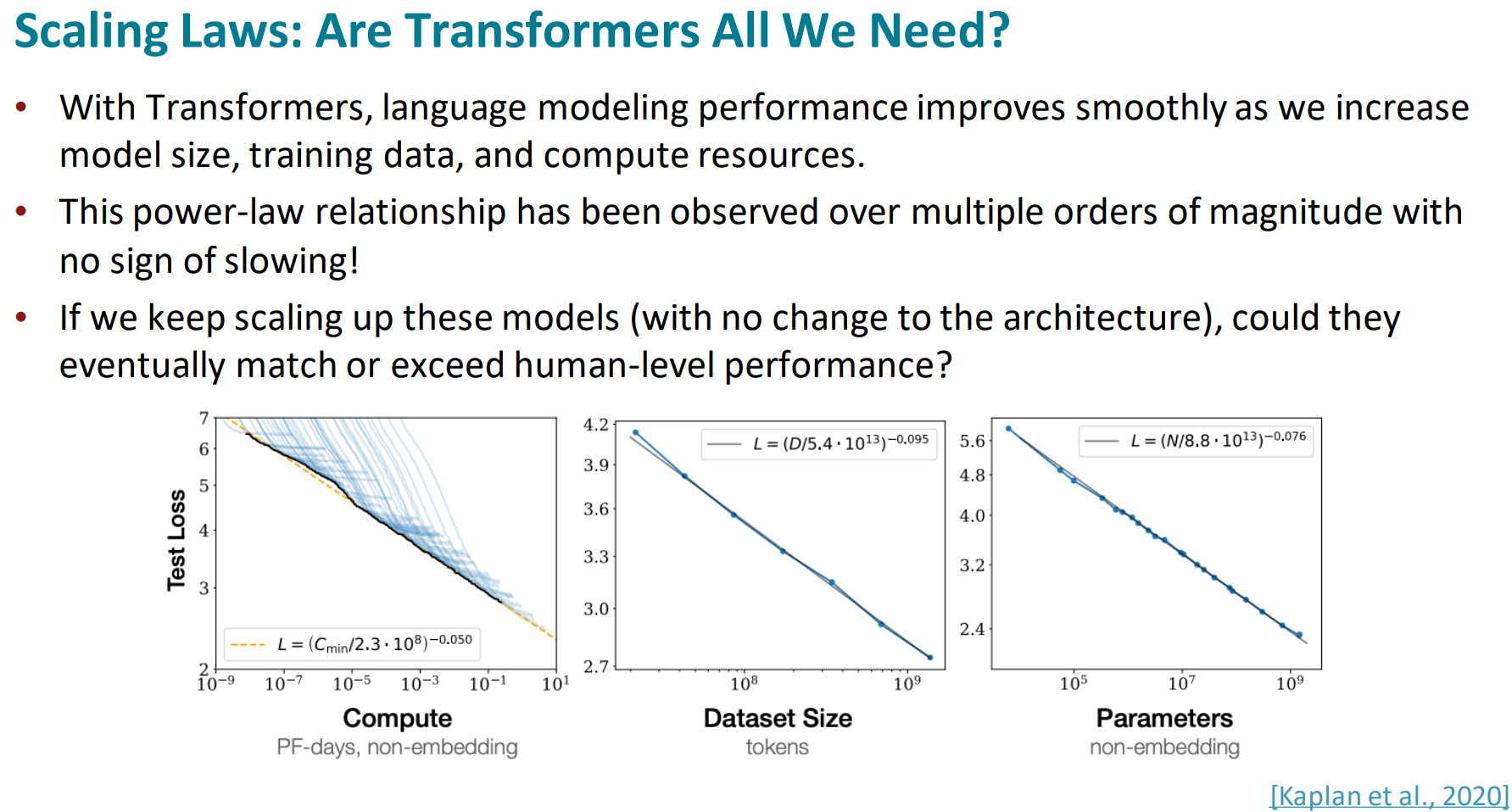
Are Transformers All We Need
Impact of Transformers on NLP (and ML more broadly)
From Recurrence (RNNs) to Attention-Based NLP Models
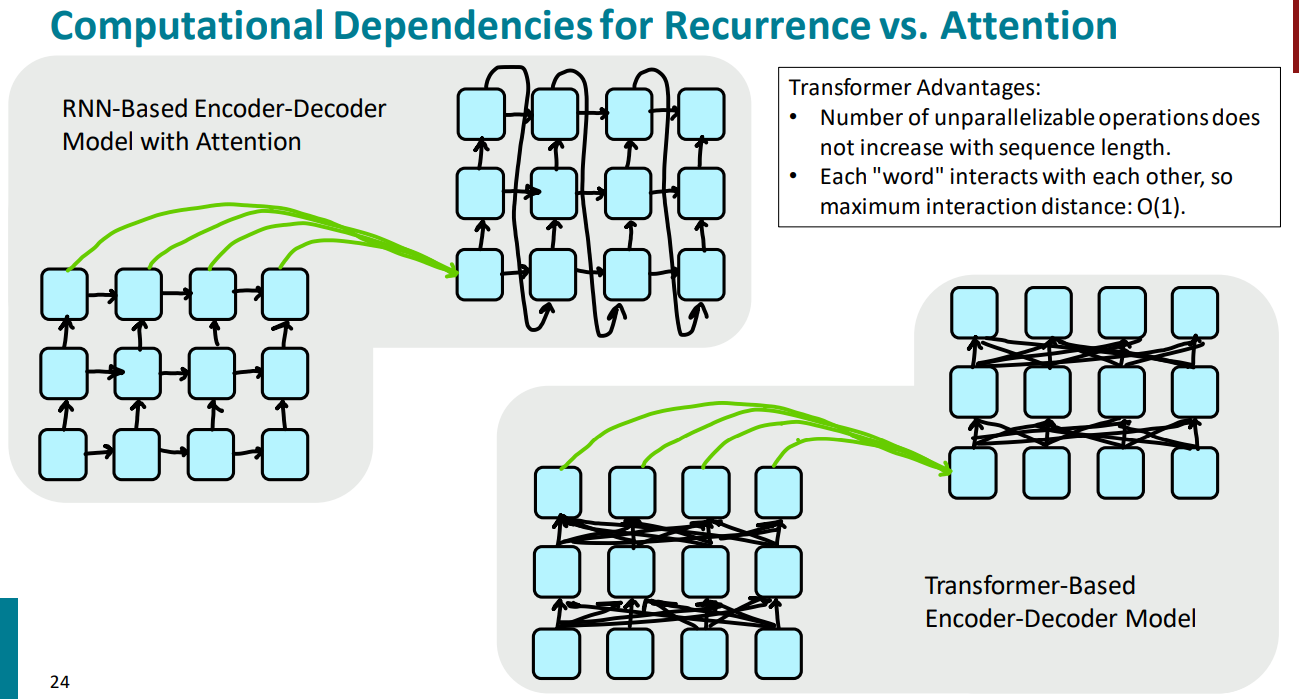
Issues with recurrent models:
- Linear interaction distance
- Lack of parallelizability
If not recurrent, then what? How about attention? Attention treats each word’s representation as a query to access and incorporate information from a set of values.
- attention from decoder to encoder
- self-attention is encoder-encoder or decoder-decoder where each words attends to each other word within the input or output.
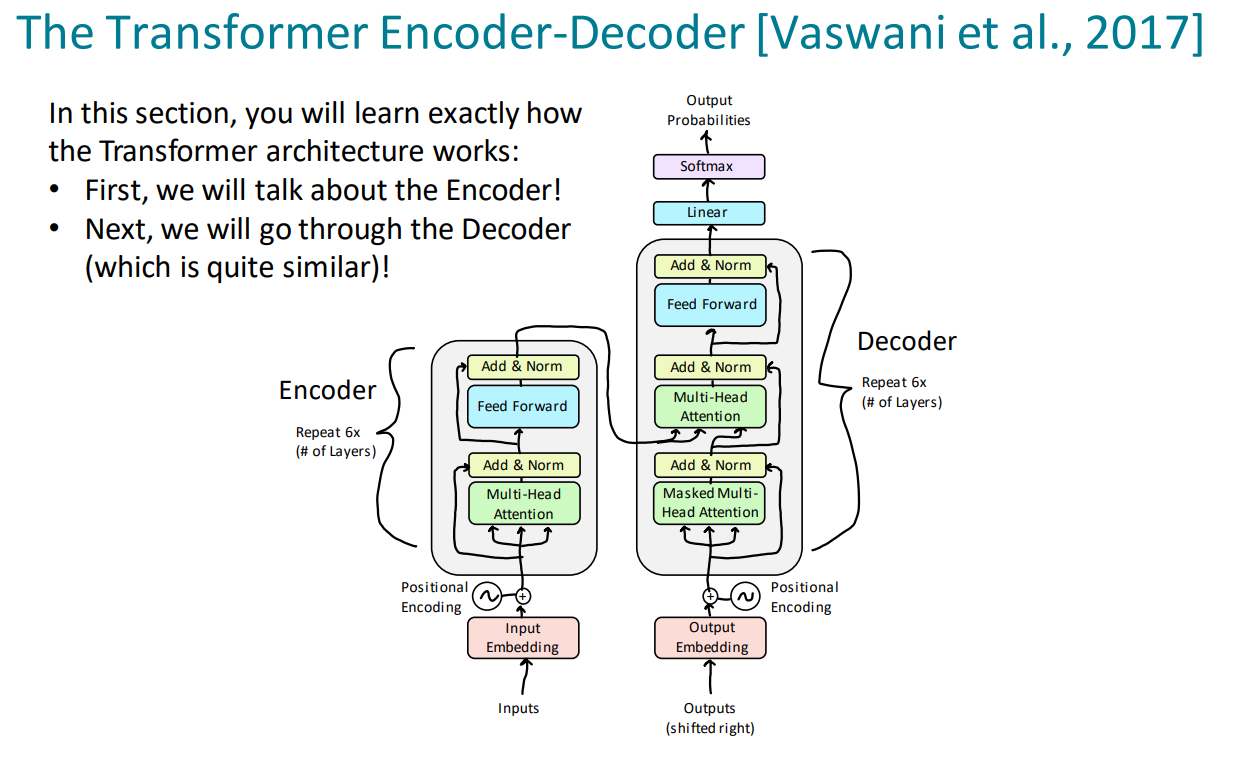
Understanding the Transformer Model
Leave a Comment