Optimized Large-Message Broadcast for Deep Learning Workloads: MPI, MPI+NCCL, or NCCL2
Background
There are new opportunities and challenges for the High-Performance Computing (HPC) community to rethink and enhance communication middleware like Message Passing Interface (MPI) and enable low-latency and high-bandwidth communication. The key idea in distributed DNN training is that local copies of DNN parameters and gradients need to be exchanged among parallel workers (or optimizers) during each training iteration. For example, CA-CNTK uses CUDA-Aware MPI_Bcast for broadcast of the model parameters as well as for gradient exchange in an all-to-all broadcast fashion.
Current state-of-the-art MPI libraries, however, are not yet ready to deal with these new DL workloads that mostly consist of very-large buffers that reside on a GPU’s memory. To this end, special-purpose communication libraries like NCCL have been developed to deal with such workloads. However, NCCL is not MPI compliant so applications need to be redesigned with new APIs. Clearly, there is a need for MPI runtimes to address these new requirements in an efficient manner so that DL applications can readily utilize MPI communication primitives for distributed training of DNNs.
CUDA-Aware MPI
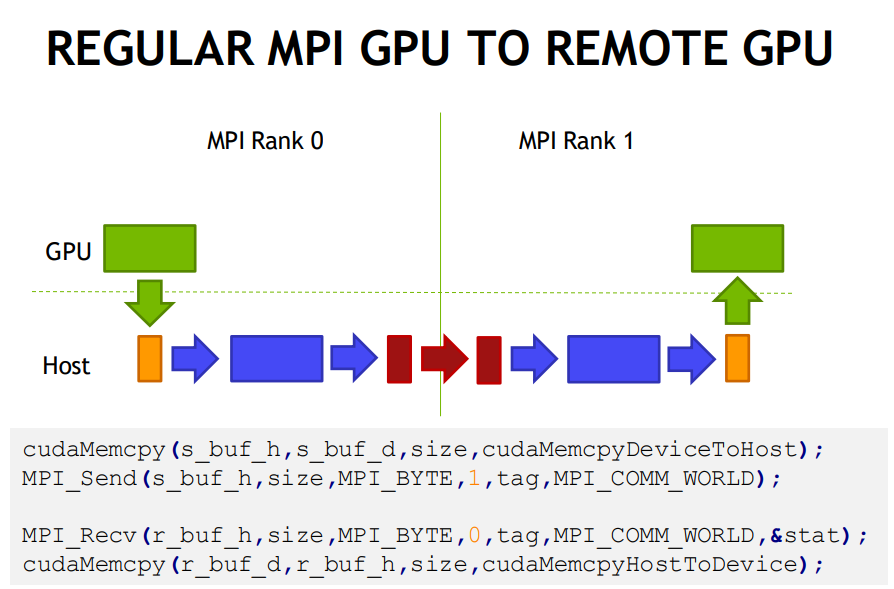
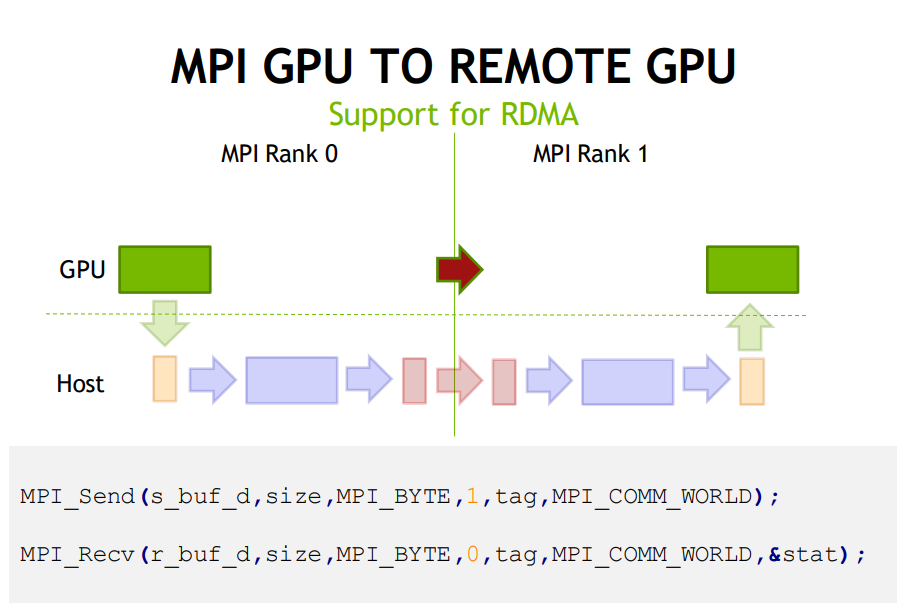
Initially, without the capability of direct access of GPU memory, MPI applications required explicit copying of GPU data to a staging buffer on the host memory in order to push the data to the network. Similarly, a data movement from CPU to GPU was needed after receiving the data on the host through an MPI_Recv opera- tion. This significantly impacts performance as well as productivity. Thus, several MPI libraries including OpenMPI and MVAPICH2-GDR provide CUDA-Aware MPI primitives to transparently perform such copy operations. These CUDA-Aware MPI libraries significantly improve performance and productivity for CUDA-enabled (MPI+CUDA) applications.
NVIDIA NCCL for GPU-based collective communication
Precisely, NCCL’s goal is to provide fast communication of messages between GPUs in dense multi-GPU machines like the DGX-1 and DGX-2 for DL workloads. In this sense, NCCL is a special-purpose GPU-optimized collective communication library.
However, the original NCCL1 li- brary was limited to only a single node multi-GPU configura- tion where GPUs are attached to a PCIe/NVLink interconnect.
Despite being similar to MPI, NCCL’s design goals and the target platforms are different. MPI is geared towards efficient communication across thousands of nodes in a cluster while NCCL is optimized for dense multi-GPU systems.
Advanced pipelining schemes for large-message broadcast
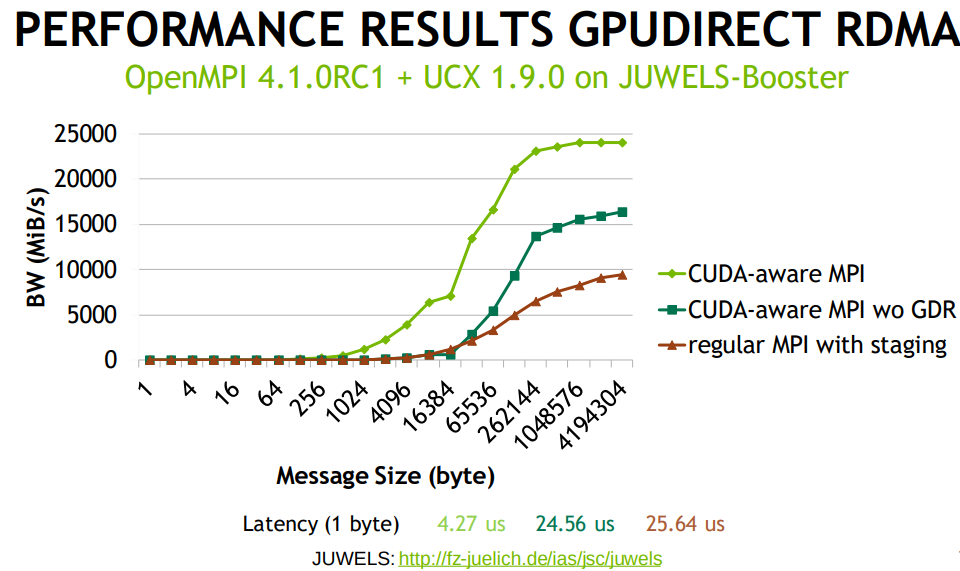
To better utilize the net- work resources, i.e., to saturate the available bandwidth, pipelin- ing schemes that divide the message into multiple smaller chunks need to be explored. Issuing multiple non-blocking point-to-point communication calls, i.e., MPI_Isend, MPI_Irecv, to allow overlap of these transfers is one strategy to implement a pipelined broadcast that achieves better bandwidth utilization. Classically, the chain (or ring) algorithm has been considered an inefficient algorithm by MPI implementers. However, with the advent of Deep Learning applications, very large message transfers and a relatively smaller number of nodes (GPUs) are becoming a new use-case for MPI run- times. Thus, the conventional intuition around the broadcast algo- rithms needs to be revisited.
Link to paper
Link to Multi-GPU Programming with CUDA, GPUDirect, NCCL, NVSHMEM, and MPI
Leave a Comment