NCCL Ring vs Tree for Multi-Node LLM Fine-Tuning
TL;DR — We benchmarked NCCL Ring, Tree, and Default allreduce algorithms across 1–8 nodes (8–64 H100 GPUs) on Azure ND H100 v5 with InfiniBand, fine-tuning both a dense model (Qwen 7B) and a Mixture-of-Experts model (Mixtral 8x7B). Each configuration was run once, so small differences may be noise. The bottom line: NCCL’s default algorithm selection works well — there is no consistent benefit to forcing Ring or Tree at any scale we tested.
Motivation
NCCL (NVIDIA Collective Communications Library) uses heuristics to pick a communication algorithm for each collective operation. The two main allreduce algorithms are:
- Ring: tokens circulate around a ring of GPUs — bandwidth-optimal but latency grows with GPU count.
- Tree: binary tree reduce + broadcast — lower latency at scale but can underutilize bandwidth on small groups.
Most practitioners never touch NCCL_ALGO. Should they? We tested this on a real fine-tuning workload at cluster scale.
Setup
| Component | Details |
|---|---|
| Cluster | Azure ND H100 v5 VMSS — up to 8 nodes × 8 GPUs = 64 H100 80GB |
| Interconnect | 400 Gb/s NDR InfiniBand (8 NICs/node), NVLink intra-node |
| Container | nvcr.io/nvidia/pytorch:24.12-py3 — PyTorch 2.6, NCCL 2.23.4, CUDA 12.6 |
| Distributed | FSDP FULL_SHARD, MixedPrecision bf16, torchrun |
| Training | seq_len=512, per_device_batch=1, 30 steps (5 warmup, 25 measured) |
| Filesystem | Azure Managed Lustre (/lustre) shared across all nodes |
| Models | Qwen2.5-7B (dense, 7.6B params) · Mixtral-8x7B-v0.1 (MoE, 46.7B params) |
NCCL algorithm was forced via environment variable:
# Default — let NCCL choose
(no NCCL_ALGO set)
# Force Tree
export NCCL_ALGO=Tree
# Force Ring
export NCCL_ALGO=Ring
Each configuration ran at 1, 2, 4, and 8 nodes. Single-node runs used Default only (no inter-node communication = no algorithm choice to make).
Results
Qwen 7B (Dense Model)
| Nodes | GPUs | Default | Tree | Δ | Ring | Δ |
|---|---|---|---|---|---|---|
| 1 | 8 | 19,106 | — | — | — | — |
| 2 | 16 | 38,299 | 38,481 | +0.5% | 37,286 | −2.6% |
| 4 | 32 | 68,691 | 74,322 | +8.2% | 72,170 | +5.1% |
| 8 | 64 | 118,384 | 116,431 | −1.6% | 117,256 | −1.0% |
Throughput in tokens/sec. Δ = % change vs Default.
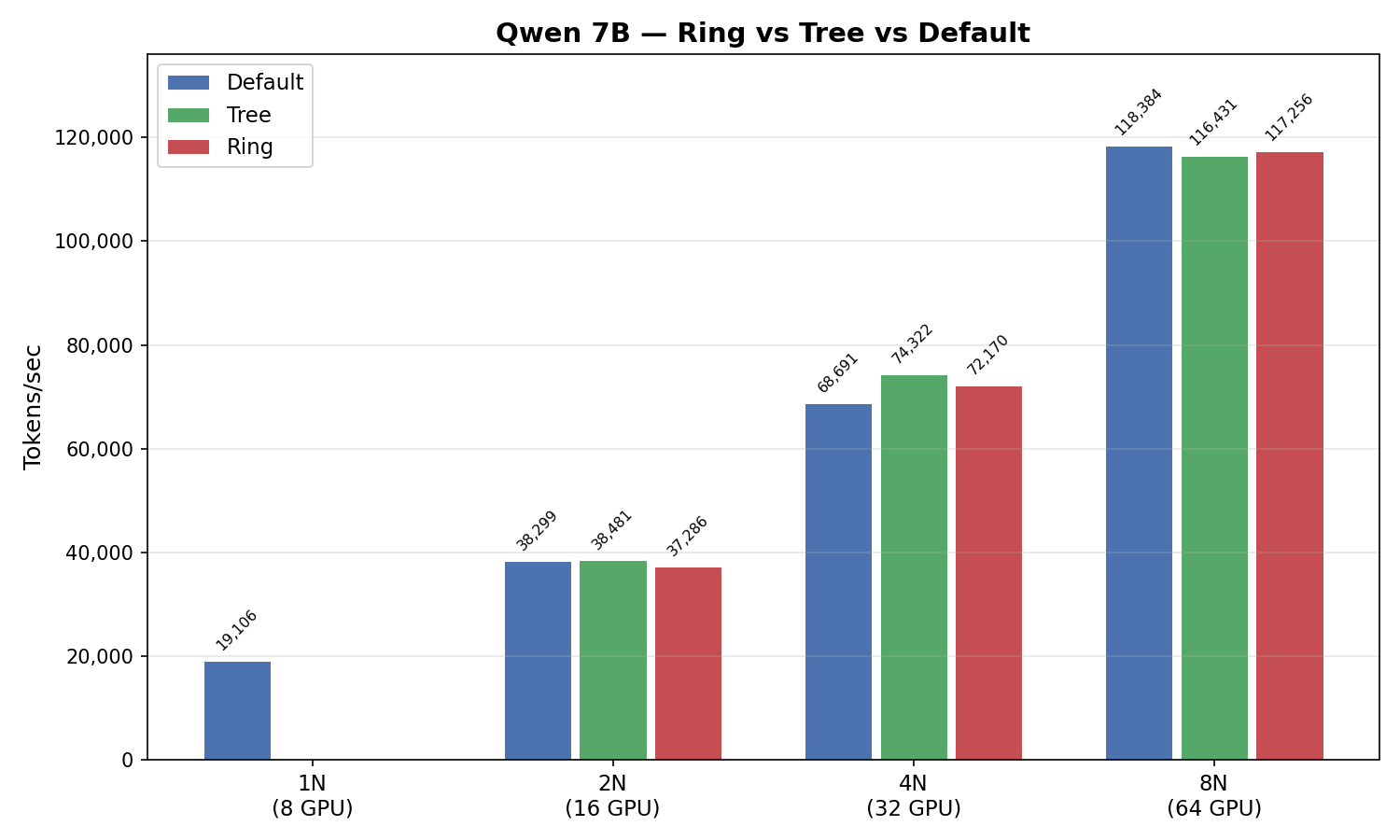
Observation: We saw some variation across scales — for example, Tree measured 8.2% higher at 4 nodes but 1.6% lower at 8 nodes. However, since each configuration was only run once (N=1), these differences could reflect normal run-to-run variance rather than a real algorithmic advantage. The key takeaway is that no forced algorithm consistently beat Default.
Mixtral 8x7B (MoE Model)
| Nodes | GPUs | Default | Tree | Δ | Ring | Δ |
|---|---|---|---|---|---|---|
| 1 | 8 | 3,339 | — | — | — | — |
| 2 | 16 | 6,542 | 6,483 | −0.9% | 6,371 | −2.6% |
| 4 | 32 | 12,506 | 12,530 | +0.2% | 12,710 | +1.6% |
| 8 | 64 | 24,482 | 23,662 | −3.3% | 24,342 | −0.6% |
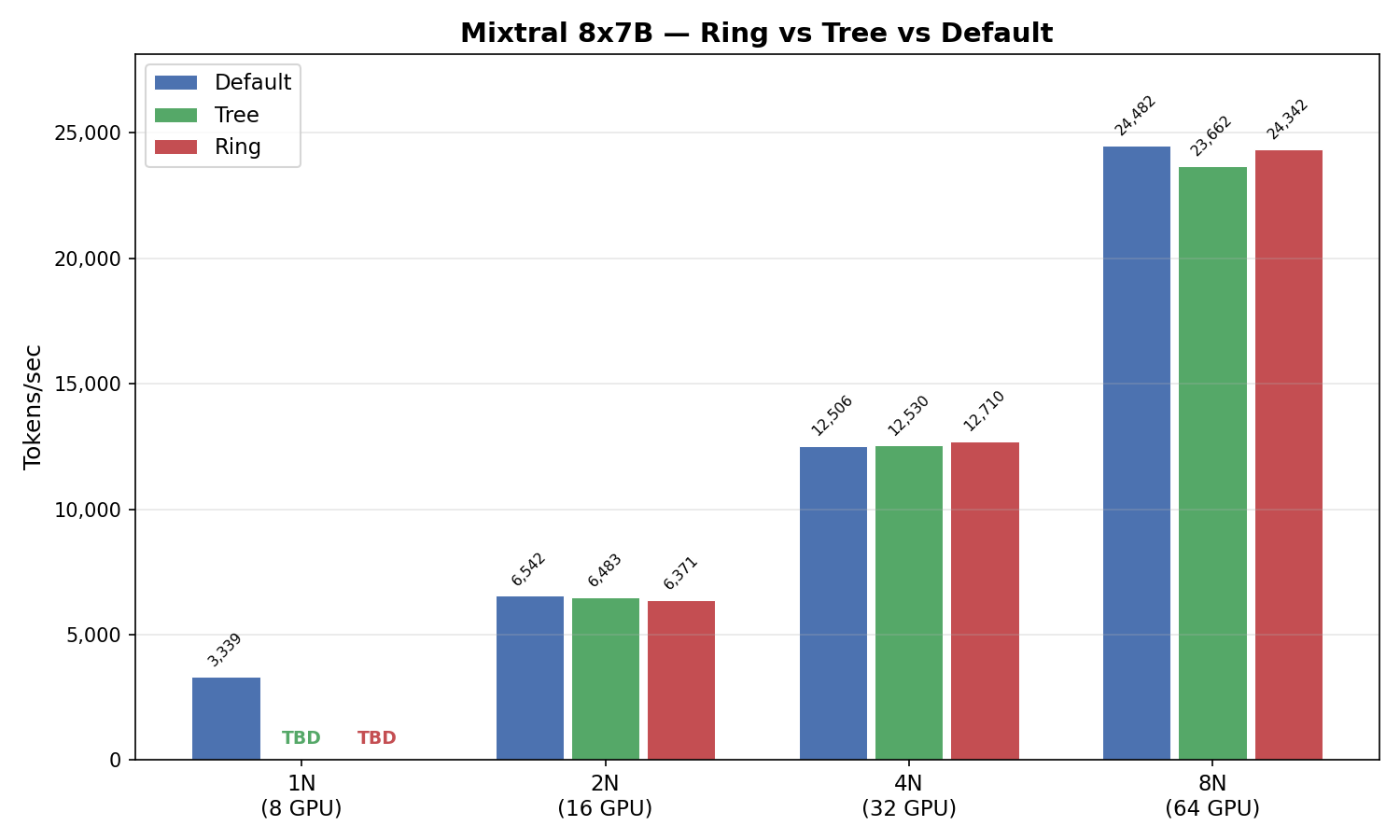
For MoE, the differences were small across the board — under 3% at most scales. With only a single run per configuration, none of these gaps are statistically meaningful. Default performed well throughout.
Percentage Change Heatmap
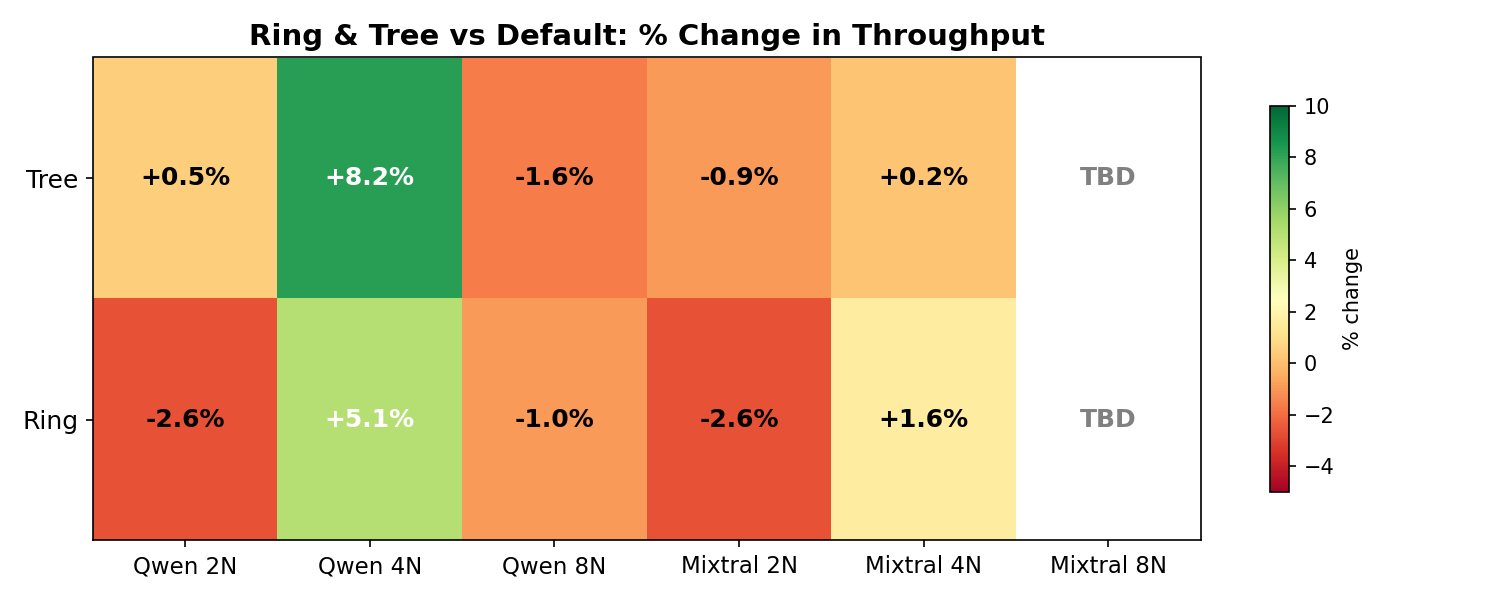
The heatmap visualizes the percentage differences. While some cells appear green or red, keep in mind that each data point is a single run — the observed variation is likely within normal noise margins.
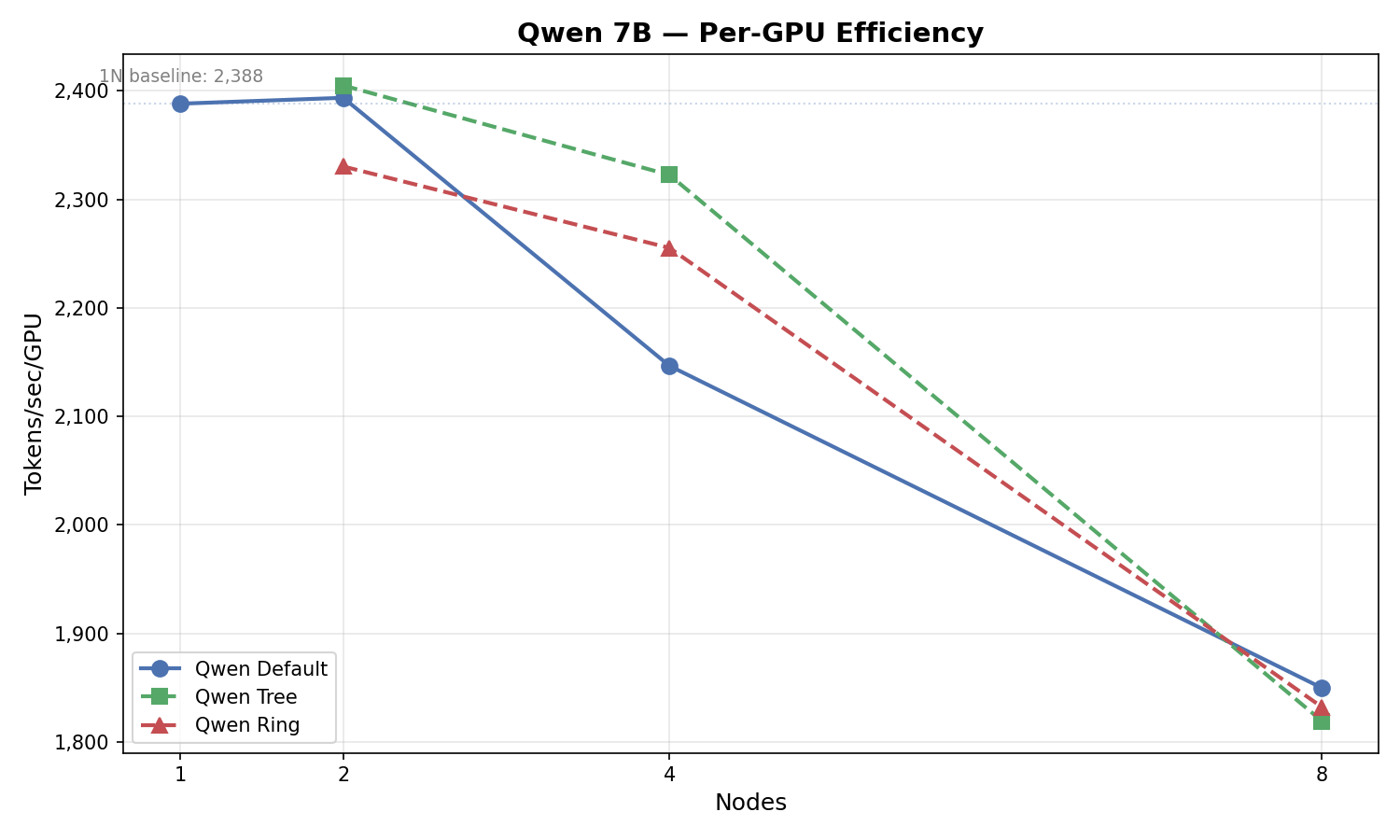
Scaling Efficiency
How well does each model scale from 1 to 8 nodes?
| Model | 1N (tok/s/GPU) | 8N (tok/s/GPU) | 8N Scaling Efficiency |
|---|---|---|---|
| Qwen 7B | 2,388 | 1,850 | 77.5% |
| Mixtral 8x7B | 417 | 383 | 91.7% |
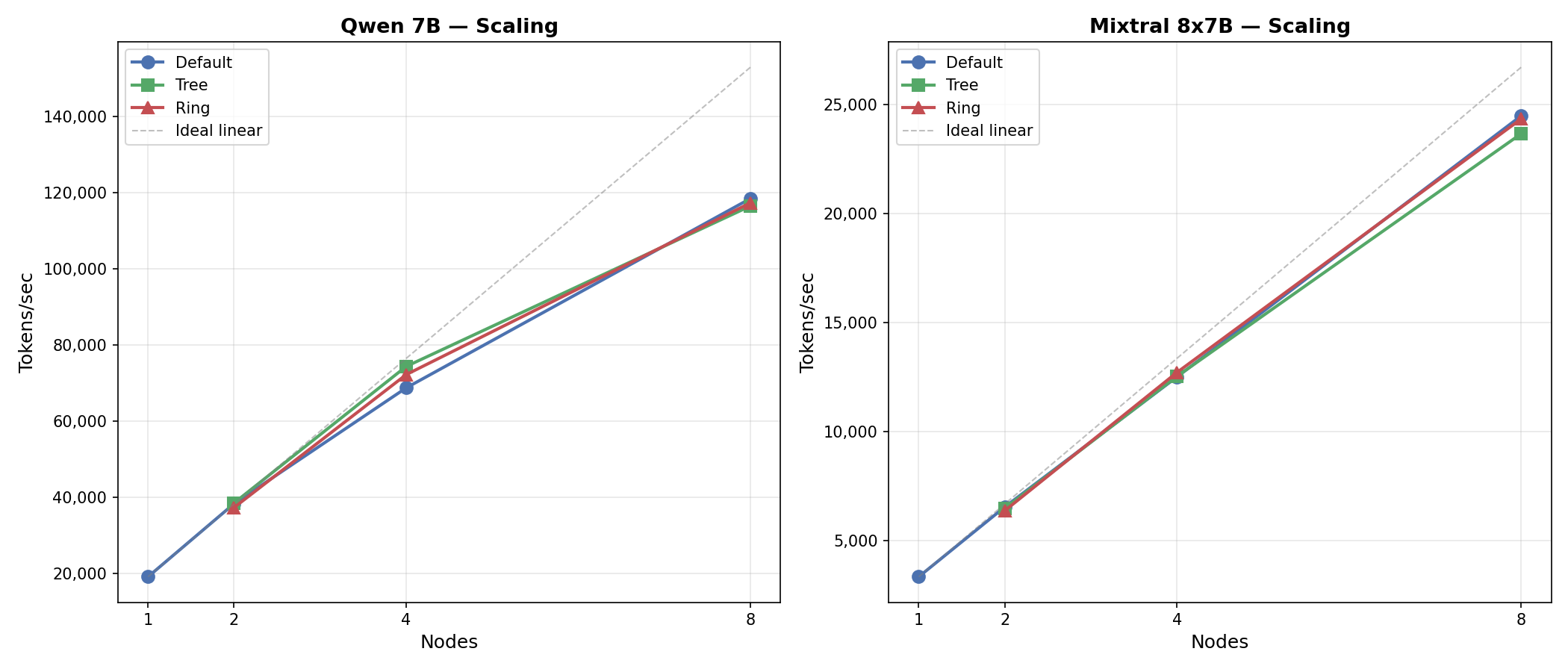
Mixtral scales remarkably well — 91.7% efficiency from 1 to 8 nodes (7.33× on 8× hardware). The MoE architecture’s smaller per-expert parameter count means each collective operation moves less data, leaving the InfiniBand fabric less congested.
Qwen’s 77.5% efficiency is still respectable for FSDP FULL_SHARD across 64 GPUs, where every forward/backward pass triggers allgather and reduce-scatter operations across all nodes.
Analysis
Could Tree actually help at intermediate scales?
The 8.2% difference at 4 nodes for Qwen is the largest gap we observed. In theory, Tree’s O(log N) latency could help at intermediate scales where Ring’s O(N) latency overhead is noticeable but data volumes are not yet large enough to favor Ring’s bandwidth optimality. However, with N=1 runs, we cannot distinguish a real algorithmic effect from run-to-run variance. A proper conclusion would require multiple repetitions per configuration.
Why is MoE less sensitive?
Mixtral’s MoE layers use expert parallelism where each GPU handles a subset of experts. The primary communication is:
- All-to-all for token routing (not affected by
NCCL_ALGO) - Allreduce for the non-expert shared parameters (attention layers, embeddings)
Since only ~30% of Mixtral’s parameters are shared (non-expert), the allreduce volume is much smaller than Qwen’s, where 100% of parameters go through allreduce. Smaller messages mean the Ring vs Tree choice matters less — both finish quickly.
Should you tune NCCL_ALGO?
No. Based on our results:
- Default was the best or near-best choice at every scale (2–8 nodes) for both models.
- The largest observed differences (e.g., +8% for Qwen Tree at 4N) come from single runs and may not be reproducible.
- Forcing an algorithm can hurt performance (e.g., Tree at 8N was slower for both models).
Trust NCCL’s defaults. The heuristics are well-tuned for modern InfiniBand clusters.
Reproduction
All experiments used this NCCL configuration:
NCCL_IB_DISABLE=0 # InfiniBand enabled
NCCL_SOCKET_IFNAME=eth0 # Control plane interface
NCCL_TOPO_FILE=/opt/microsoft/ndv5-topo.xml # Azure ND H100 v5 topology
NCCL_DEBUG=WARN
Algorithm was forced by adding:
NCCL_ALGO=Ring # or Tree, or omit for Default
Training scripts, sweep automation, and monitoring setup are available in the companion repository.
Takeaways
- NCCL defaults work. Default matched or beat forced algorithms at every scale we tested for both model architectures.
- No algorithm consistently won. The observed differences were small and based on single runs — not enough to make reliable recommendations for Ring or Tree at any specific scale.
- MoE models are algorithm-insensitive — all three algorithms performed within 3% for Mixtral at every node count.
- Scaling efficiency matters more. Mixtral’s 91.7% efficiency vs Qwen’s 77.5% dwarfs any algorithm-level difference.
- Don’t tune NCCL_ALGO. Spend engineering effort on model parallelism strategy, batch size, and activation checkpointing instead.
This is a personal blog. Opinions and recommendations are my own, not Microsoft’s.
Leave a Comment