SLURM Hybrid Cluster Setup in Azure
This post is to demonstrate how to setup SLURM federation between an on-prem cluster and an Azure cluster. Both clusters will be deployed by azhop. Please refer to the azhop documentation on how to deploy an HPC environment on Azure.
About SLURM federation
Slurm Federation is a feature of the Slurm Workload Manager, a highly scalable and flexible open-source cluster management and job scheduling system commonly used in high-performance computing (HPC) environments.
A Slurm Federation allows multiple independent clusters to be connected and managed as a single entity. This enables users to submit jobs to the federation as a whole, rather than to a specific cluster. The jobs are then automatically routed to the appropriate cluster for execution, based on the available resources and the job requirements. This can help to improve the utilization of resources across multiple clusters, increase the efficiency of job scheduling, and provide a more seamless user experience.
In a Slurm Federation, each participating cluster is considered a member of the federation and operates as a separate entity. The members communicate with each other using the Slurm messaging layer, and a centralized management entity is responsible for coordinating the scheduling and execution of jobs across the federation.
Slurm Federation is a relatively new feature, and its implementation and use can be complex. However, it has the potential to greatly enhance the capabilities of HPC systems and support the efficient use of resources in large-scale computing environments.
Add scheduler node network security group (NSG) rules and setup virtual network peering
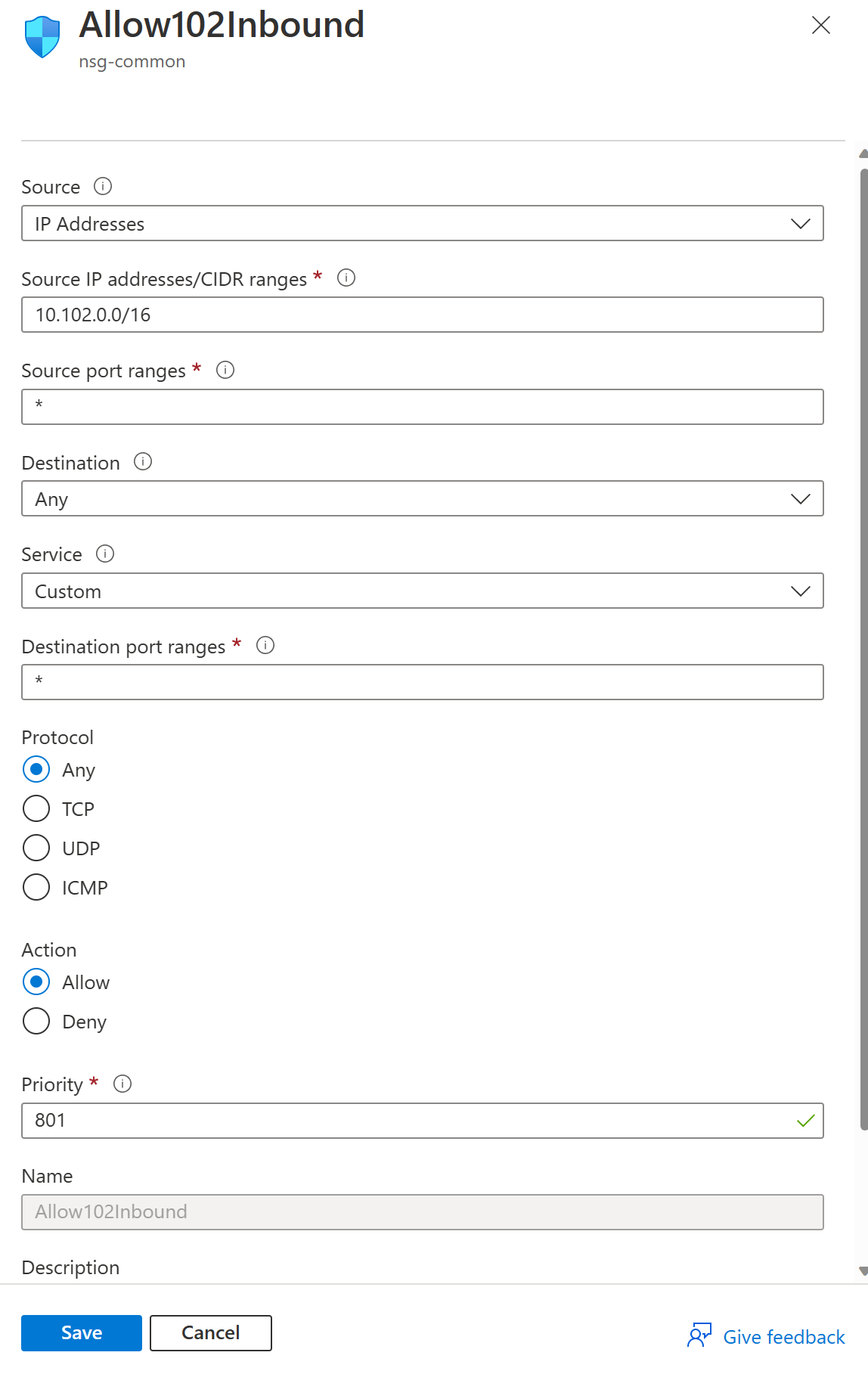
To setup SLURM federation we need to enable slurmdbd communications between on-prem and cloud clusters. New NSG rules and vnet peering need to be added to enable the commnucation.
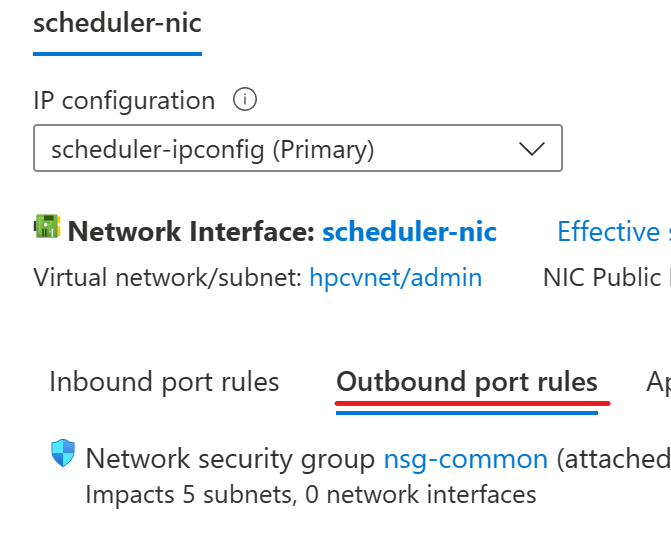
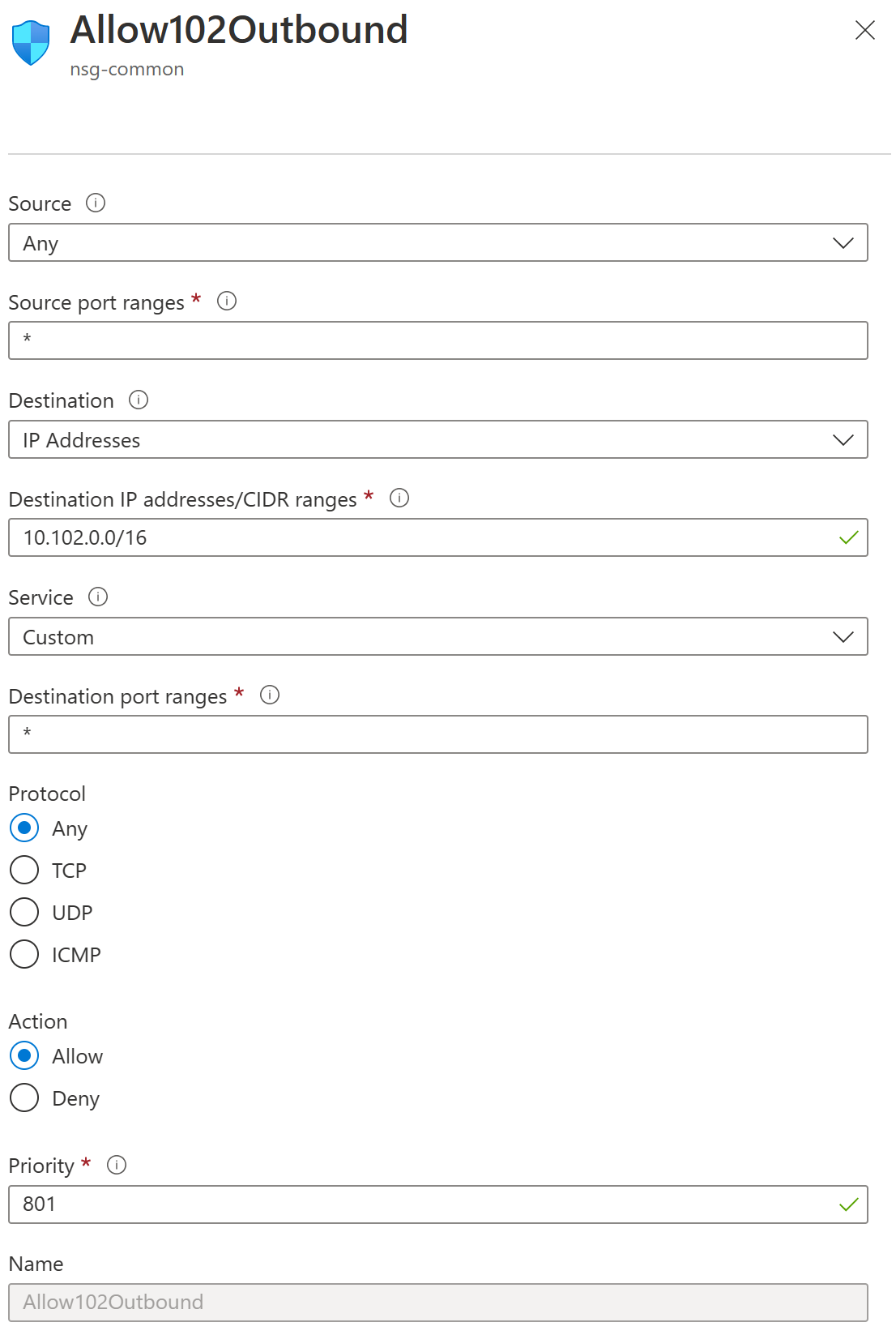
First go to the scheduler node which hosts the slurmdbd and add inbound/outbound rules. This needs to be done from both on-prem and cloud scheduler nodes.
Then add vnet peering from either the on-prem or the cloud end. The other end will be created automatically.
Sync the munge key
Copy the on-prem munge key from /etc/munge/munge.key
[root@scheduler ~]# cat /etc/munge/munge.key
Paste and replace the munge key to the cloud cluster in two locations.
[root@scheduler ~]# ls /etc/munge/munge.key /sched/munge/munge.key
/etc/munge/munge.key /sched/munge/munge.key
The first munge.key is local to the scheduler node, and the second munge key is used to populate to the compute nodes.
Once the munge key is replaced on the cloud cluster, restart the munge daemon.
[root@scheduler ~]# systemctl restart munge.service
[root@scheduler ~]# systemctl status munge.service
● munge.service - MUNGE authentication service
Loaded: loaded (/usr/lib/systemd/system/munge.service; enabled; vendor preset: disabled)
Active: active (running) since Thu 2023-02-09 21:05:50 UTC; 7s ago
Docs: man:munged(8)
Process: 14428 ExecStart=/usr/sbin/munged (code=exited, status=0/SUCCESS)
Main PID: 14430 (munged)
Tasks: 4
Memory: 516.0K
CGroup: /system.slice/munge.service
└─14430 /usr/sbin/munged
Feb 09 21:05:50 scheduler systemd[1]: Starting MUNGE authentication service...
Feb 09 21:05:50 scheduler systemd[1]: Started MUNGE authentication service.
Rename the SLURM cluster if desired
SLURM cluster name is defined in the /etc/slurm/slurm.conf file
[root@scheduler ~]# vim /etc/slurm/slurm.conf
Change the line below
ClusterName=cloud
Delete the cached cluster name and restart SLURM controller daemon
rm /var/spool/slurmd/clustername
[root@scheduler ~]# systemctl restart slurmctld.service
[root@scheduler ~]# systemctl status slurmctld.service
● slurmctld.service - Slurm controller daemon
Loaded: loaded (/usr/lib/systemd/system/slurmctld.service; enabled; vendor preset: disabled)
Active: active (running) since Thu 2023-02-09 21:11:22 UTC; 5s ago
Main PID: 15833 (slurmctld)
Tasks: 5
Memory: 2.8M
CGroup: /system.slice/slurmctld.service
└─15833 /usr/sbin/slurmctld -D
Feb 09 21:11:22 scheduler systemd[1]: Started Slurm controller daemon.
Point the cloud cluster to use on-prem slurmdbd
The slurmdbd host IP is configured in the /etc/slurm/slurm.conf file.
Change the following setting in the cloud cluster.
AccountingStorageHost=ON_PREM_SLURMDBD_HOST_IP
Note: AccountingStorageHost does NOT need to be changed in the on-prem /etc/slurm/slurm.conf file.
Add the following line to the bottom of on-prem /etc/slurm/slurm.conf file for federation clusters display (optinal).
FederationParameters=fed_display
Restart slurm controller and slurmdbd on both on-prem and cloud clusters.
[root@scheduler ~]# systemctl restart slurmctld.service; systemctl restart slurmdbd.service
[root@scheduler ~]# systemctl status slurmctld.service; systemctl status slurmdbd.service
● slurmctld.service - Slurm controller daemon
Loaded: loaded (/usr/lib/systemd/system/slurmctld.service; enabled; vendor preset: disabled)
Active: active (running) since Thu 2023-02-09 21:18:02 UTC; 15s ago
Main PID: 17549 (slurmctld)
Tasks: 15
Memory: 3.6M
CGroup: /system.slice/slurmctld.service
└─17549 /usr/sbin/slurmctld -D
Feb 09 21:18:02 scheduler systemd[1]: Started Slurm controller daemon.
● slurmdbd.service - Slurm DBD accounting daemon
Loaded: loaded (/usr/lib/systemd/system/slurmdbd.service; enabled; vendor preset: disabled)
Active: active (running) since Thu 2023-02-09 21:18:02 UTC; 15s ago
Main PID: 17560 (slurmdbd)
Tasks: 1
Memory: 948.0K
CGroup: /system.slice/slurmdbd.service
└─17560 /usr/sbin/slurmdbd -D
Feb 09 21:18:02 scheduler systemd[1]: Stopping Slurm DBD accounting daemon...
Feb 09 21:18:02 scheduler systemd[1]: Stopped Slurm DBD accounting daemon.
Feb 09 21:18:02 scheduler systemd[1]: Started Slurm DBD accounting daemon.
Note: The change may take a few minutes to become effective
Verify the clusters and create the federation from the cloud cluster
[root@scheduler ~]# lsid
Slurm 20.11.9, Nov 1 2020
Copyright SchedMD LLC, 2010-2017.
My cluster name is cloud
My master name is scheduler
[root@scheduler ~]# sacctmgr show cluster format=cluster,controlhost,controlport
Cluster ControlHost ControlPort
---------- --------------- ------------
cloud 10.107.0.22 6817
on-prem 10.115.0.20 6817
Create the federation
sacctmgr add federation cloudburst clusters=on-prem,cloud
Verify the federation
[root@scheduler ~]# sacctmgr list federation
Federation Cluster ID Features FedState
---------- ---------- -- -------------------- ------------
cloudburst cloud 2 ACTIVE
cloudburst on-prem 1 ACTIVE
[root@scheduler ~]# sinfo
PARTITION CLUSTER AVAIL TIMELIMIT NODES STATE NODELIST
execute* cloud up infinite 1 alloc# execute-pg0-2
execute* on-prem up infinite 3 idle# execute-pg0-[1-3]
execute* cloud up infinite 511 idle~ execute-pg0-[1,3-100],execute-pg1-[1-100],execute-pg2-[1-100],execute-pg3-[1-100],execute-pg4-[1-100],execute-pg5-[1-12]
execute* on-prem up infinite 509 idle~ execute-pg0-[4-100],execute-pg1-[1-100],execute-pg2-[1-100],execute-pg3-[1-100],execute-pg4-[1-100],execute-pg5-[1-12]
hb120v2 on-prem up infinite 24 idle~ hb120v2-pg0-[1-24]
hb120v2 cloud up infinite 24 idle~ hb120v2-pg0-[1-24]
hb120v3 on-prem up infinite 24 idle~ hb120v3-pg0-[1-24]
hb120v3 cloud up infinite 24 idle~ hb120v3-pg0-[1-24]
hb60rs on-prem up infinite 24 idle~ hb60rs-pg0-[1-24]
hb60rs cloud up infinite 24 idle~ hb60rs-pg0-[1-24]
hbv3u18 on-prem up infinite 24 idle~ hbv3u18-pg0-[1-24]
hbv3u18 cloud up infinite 24 idle~ hbv3u18-pg0-[1-24]
hc44rs on-prem up infinite 24 idle~ hc44rs-pg0-[1-24]
hc44rs cloud up infinite 24 idle~ hc44rs-pg0-[1-24]
largeviz3d on-prem up infinite 2 idle~ largeviz3d-[1-2]
largeviz3d cloud up infinite 2 idle~ largeviz3d-[1-2]
nc24v3 on-prem up infinite 4 idle~ nc24v3-pg0-[1-4]
nc24v3 cloud up infinite 4 idle~ nc24v3-pg0-[1-4]
viz on-prem up infinite 12 idle~ viz-[1-12]
ndamsv4 cloud up infinite 1 idle~ ndamsv4-1
viz3d on-prem up infinite 4 idle~ viz3d-[1-4]
viz cloud up infinite 8 idle~ viz-[1-8]
viz3d cloud up infinite 4 idle~ viz3d-[1-4]
Submit test jobs from the on-prem cluster
[root@scheduler ~]# cat submit.sh
#!/bin/bash
#SBATCH -N 1
#SBATCH --output=job.%J.out
#SBATCH --error=job.%J.err
hostname
sleep 120
[root@scheduler ~]# sbatch -M cloud submit.sh
Submitted batch job 134217753 on cluster cloud
[root@scheduler ~]# sbatch -M on-prem submit.sh
Submitted batch job 67108878 on cluster on-prem
[root@scheduler ~]# sbatch submit.sh
Submitted batch job 67108879
[root@scheduler ~]# squeue
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
134217753 execute submit.s root CF 0:18 1 execute-pg0-3
67108879 execute submit.s root CF 0:05 1 execute-pg0-4
67108878 execute submit.s root CF 0:12 1 execute-pg0-1
[root@scheduler ~]#
Leave a Comment